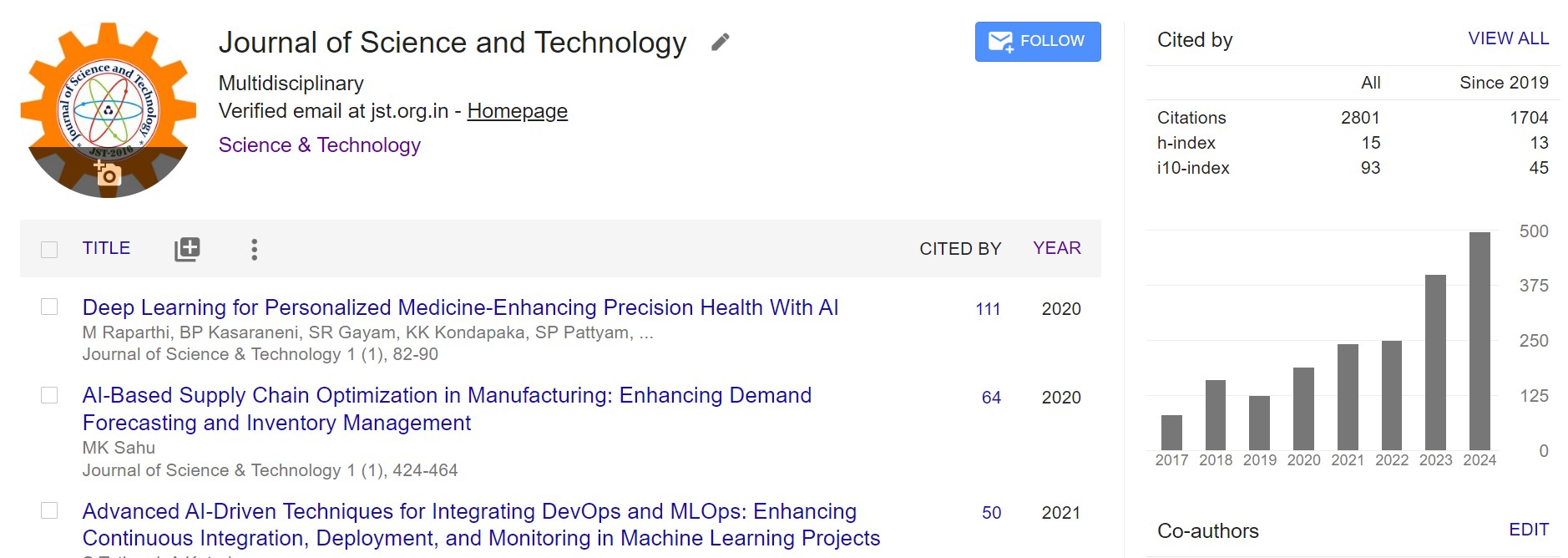
Revolutionizing Audio Content Navigation: AI-Enhanced Multimodality and Machine Learning for Speaker Diarization and Topic Segmentation
DOI:
https://doi.org/10.46243/jst.2025.v10.i01.pp10-25Keywords:
Speaker Diarization,, Topic Segmentation,, , Artificial Intelligence(AI),, Machine Learning, Multimodal Processing,, , Natural Language Processing(NLP),, Content Navigation, Deep Learning.Abstract
The rapid evolution of digital media has propelled an increased
consumption of audio content, ranging from podcasts to educational lectures.
Despite its growing popularity, the inherent unstructured nature of audio media
poses significant challenges in navigation and user interaction. Our paper
introduces an innovative AI-driven framework designed to fundamentally
transform audio content exploration. Utilizing cutting-edge machine learning and
deep learning technologies, the system applies precise speaker diarization and
topic segmentation to radically improve navigation and content discovery in
audio streams. Furthermore, the incorporation of an interactive chat feature
enriches user interaction, allowing listeners to effortlessly query and jump
directly to specific content via intuitive voice and text commands. This advanced
system not only streamlines the audio exploration process but also personalizes
the listener experience by integrating multimodal interfaces and sophisticated
content annotation techniques. By addressing critical navigational inefficiencies,
this framework sets a new paradigm in personalized, structured, and interactive
media consumption, catering to the evolving demands of modern audio content
users.
Downloads
Published
How to Cite
Issue
Section